I’ve realized for a long time that 2 layer multilayer perceptron (MLP) neural nets, the kind I’ve mainly built up till now, are fundamentally limited. A neural net’s strength comes from its depth. The more layers you have, the higher the degree of the polynomial model it creates to map from a given vector input to a desired vector output. At least, that’s how I interpret it. Each layer functions like a linear regressor. Each subsequent layer multiplies its regression by the previous regression. If you’ve ever multiplied the formulas for two linear equations, it gives you a quadratic equation. In other words, your model goes from being a straight line, which often is not useful enough, to a curvy line, which is more useful. Multiply that curvy model again and you can handle data containing more elaborate curvature.
So obviously, I’ve been wanting to build what’s called a deep neural network, which is a NN that has more than 1 hidden layer. In effect, it has more than 2 layers (hidden and output). Input neurons don’t calculate and so don’t contribute to modelling. The trouble with MLPs, however, is that back-propagation is… unpleasant. The model first feeds the inputs forward through the entire network. This leads to some outputs. The outputs have error. The network tries to lower the error a bit by calculating the error caused by each weight. It reduces that error a little bit by using the slope of the derivative of total error with respect to each individual weight (each has its own unique calculation) and moving down that slope. This is called gradient descent. But it does this by working backwards from the error in the final outputs and that’s the source of the suck.
At first, it’s not that bad. Calculating the error caused by the weights leading directly into the output neurons is incredibly straightforward. The error of a given weight = the change in error with respect to change in output * the change in output with respect to change in input * the change in input with respect to the change in a given weight feeding into that input. 3 primary terms and a learning coefficient and you’re ready to backpropagate. The next layer of weights is much harder to calculate, though, because it corrects for error with respect to parameters calculated for the output layer. Take it from me, it’s unpleasant. The thought of doing that again and again, more elaborately each time, as I built a deeper and deeper NN was frankly almost a deal-breaker for me.
Instead I played with some ideas in my head to backpropagate in a scalable way that isn’t a nightmare to program. Eventually, I settled on an approach that admittedly has already probably been done by someone. But because I’ve never seen such a design, I’ll take credit for at least independently coming up with it. In my own hyper-ignorant parlance, I call it an episodic deep MLP. It’s orders of magnitude easier to program, has already been built with 4 layers, and so far largely meets my expectations.
The way it works is it turns backpropagation on its head. Instead of deriving corrections from the final output results, it carries out BP on each layer as if it’s an entirely separate neural net. Then the layers are multiplied together in order. To be a bit more descriptive, layer 1 gets an input and is told what the output should be. It performs a linear regression through backpropagation and comes up with a model that is okay; certainly not amazing, but it’s okay. Once it has run for a set number of runs, it stops doing anything and the original input continues to feed forward through it, and its output serves as the input for layer 2, another NN of the same input and output dimensions. This NN is given the same targets as layer 1. But it has an advantage. It takes the previous output, which is the result of a linear regression, and performs another linear regression upon it. It’s regressing off an already regressed problem. The product of that regression is now 1 degree higher, quadratic. Then the cycle just repeats in higher layers.
The output of layer 2 becomes the input for layer 3, and onward the pattern goes until you stop feeling like adding layers. From the perspective of feeding forward, this is 100% identical to any other MLP. But from the perspective of backpropagation, it works differently. It starts with a weak regression and then hones it further. In my mind, this is analogous to drawing a straight regression line, by eye, on paper for some laboratory results and then gradually adding curvature to it until it seems like a reasonable formula for the underlying equation governing whatever phenomenon you’re interested in modelling.
Below is a picture of the 4 layer NN I built.
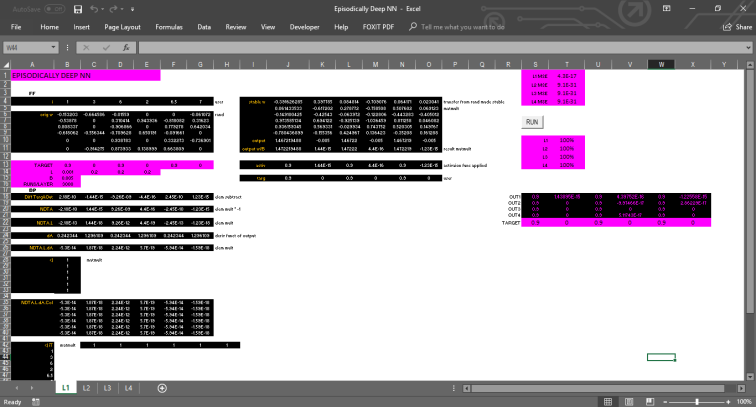
What we see here is layer 1. Each layer is a cell formula-implemented version of an array/matrix based NN I designed but have yet to implement in another language. The worksheet tab reads L1 because it houses layer 1. As you can see, there are 3 more tabs. Each of them receives the activated outputs of the previous layer in their input area. Each layer’s mean squared error (MSE) is calculated in real-time and is displayed in the pink region on the top right of the L1 page. By monitoring the network as it learns and observing errors as they occurred at different stages afterwards, it is possible to judge how well the model performs at different points in the learning process, how the global bias and learning rates for each layer should be adjusted, and hopefully, whether overfitting has occurred.
I hypothesize that an increase in MSE after a minima might serve as the basis with which to decide which layer should serve as the final layer when interrogating real world data. Since conveniently extractable outputs are generated by each layer, when given data for analysis, the program can simply pull from the layer with the best MSE automatically, after deciding that the full 4 layer model was redundant, all without having to redo the modelling. I haven’t installed this monitoring and output redirection scheme yet, but it will be very trivial to do so.
All in all, I view this as a promising, scalable, modular framework and I look forward to testing its performance.

One thought on “Quartic Eyeglasses”